Webスクレイピングとは
Webスクレイピングとは、Webページ上の情報を自動で収集するための技術です。
日々更新されるWebサイト上の情報を、手作業で収集する事は現実的ではありません。Webスクレイピングを用いて収集作業を自動化することで、業務の効率化を実現できます。
Webスクレイピングを行うには
Webスクレイピングは、プログラミングによってWebブラウザを自動操作することによって、情報収集を自動化します。
今回はWebスクレイピングを実現するためによく使われる「Python(パイソン)」というプログラム言語を用いた手順をご紹介します。
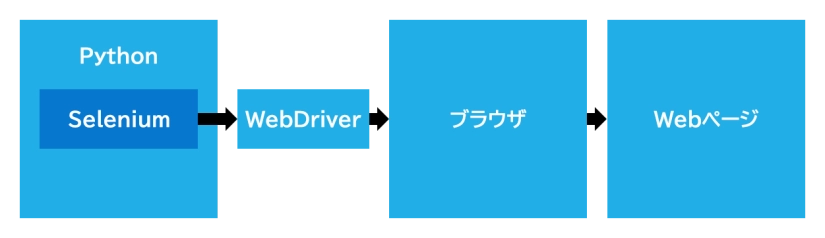
Pythonには強力なライブラリが数多く存在し、ブラウザの自動操作やHTMLの解析等を行うプログラムを書くことができます。
ブラウザの自動操作を行うためのライブラリにはいくつか候補がありますが、ここでは最も普及しているライブラリ「Selenium(セレニウム)」を用いた手順を紹介したいと思います。SeleniumはWebDriverを介してブラウザをプログラム操作します。
・プログラム言語: Python
・ブラウザ操作ライブラリ: Selenium
・操作対象のブラウザ: Google Chrome, Microsoft Edge, Firefox等
環境構築
・Pythonのインストール
プログラム言語の「Python」をインストールします。Pythonの公式ページからPython3.xをダウンロードして、インストールします。
・WebDriverのダウンロード
ここではGoogle Chromeを操作するためのWebDriverをダウンロードします。
ChromeDriverのページから、操作対象のChromeバージョンと一致するDriverをダウンロードします。
https://developer.chrome.com/docs/chromedriver?hl=ja
解凍して、任意のフォルダに配置します。
・Seleniumのインストール
コマンドプロンプト(ターミナル)から、次のコマンドを実行します。
pip install selenium
実装
ここでは、IPAのサイトから新着情報の一覧を取得するスクレイピング処理を実装してみます。
https://www.ipa.go.jp/news/index.html
「ipa_scraping.py」という名前のテキストファイルを作成して、テキストエディタで開きます。
次のコードを入力して、保存します。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = Options()
options.add_argument('--headless')
options.binary_location = 'Chromeブラウザのパス'
driver = webdriver.Chrome(service=Service('ChromeDriverのパス'), options=options)
driver.implicitly_wait(0.5)
driver.get('https://www.ipa.go.jp/news/index.html')
topics = driver.find_elements(By.CSS_SELECTOR, 'ul.news-list li p')
for topic in topics:
print(topic.text)
driver.quit()
※「Chromeブラウザのパス」の部分は、お使いのChromeのパスです。(Windowsの場合はchrome.exeファイルのパス)
※「ChromeDriverのパス」の部分は、環境構築でダウンロードしたChromeDriverのパスです。(Windowsの場合はchromedriver.exeのパス)
コードが入力できたら、コマンドプロンプト(ターミナル)を開いて、ipa_scraping.pyを実行します。成功すると、取得した一覧情報が出力されます。
python ipa_scraping.py
ソースコードの解説
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By
options = Options()
options.add_argument('--headless') # 画面を持たないヘッドレスモードで起動
options.binary_location = 'Chromeブラウザのパス' # Chromeの実行ファイルのパスを指定driver = webdriver.Chrome(service=Service('ChromeDriverのパス'), options=options)driver.implicitly_wait(0.5)
driver.get('https://www.ipa.go.jp/news/index.html')topics = driver.find_elements(By.CSS_SELECTOR, 'ul.news-list li p')
for topic in topics:
print(topic.text)driver.quit()
Chromeを終了しています。
Webスクレイピングをお考えなら『クラウドBOT』をお試しください
クラウドBOTはブラウザ操作を自動化できるクラウド型のRPAサービスです。Webスクレイピング用途でも多数の利用実績があります。複雑な環境構築をが不要であり、会員登録すると無料でWebスクレイピング用のロボットを作成できます。ロボットは基本的にノーコードで構築できますが、複雑な処理を行いたい場合は、javascriptを直接記述し、実行させることもできます。
Webスクレイピングの実装を検討されている方は是非一度お試し下さい。









